Office work with countless meetings and emails can multiply your document library to exploding proportions. Minor edits, filename changes, even "printing" a DOCX to PDF format, result in duplicate information and wasted disk space.
i-DeClone considers only the pure text content of your documents (ignoring formatting, embedded pictures and figures) and can detect similar documents using a custom AI classifier algorithm (which looks for similar blocks of text). This comparison also works for plain TXT files, CPP source code, spreadsheets — anything that is text or can be read as text.
Situation
Countless document edits and minor revisions
Countless document edits and minor revisions
Applies to
All text documents
Step by step instructions:
➀ Connect devices to scan
If you want to scan external disks, connect them, or just scan your PC folder contents. Click on Start scan toolbar button to begin. Then click Start new project to setup scan settings from scratch.➁ Scan options
|
Set the scan category to Documents as seen in the snapshot.
Set the folder to scan where you keep your documents. If you start in ThisPC then you will scan all your computer, including any mapped network drives. If you have pure \\network\shares to search for office work, you can add them on top too. Tick Find similar files option and leave the tolerance level to 90%. If you reduce this number then you will find documents that were more heavily modified as "duplicates" — including sadly more false alarms too! If your aim is to discover the same document saved as DOC and PDF, switch to advanced page and clear the box Files must have same extension. In that case you will probably want to increase the tolerance level to 95% or more, to find exact documents in different file formats. Note that filesize is used for sorting, so this method will fail if sizes differ a lot. If the filenames are the same except for the extension, then instead of Size use Plain name as the guiding property. This will catch documents with same base names e.g. REPORT.DOC and REPORT.PDF as long as they have similar content too All set, click Start scan and wait for the results. |
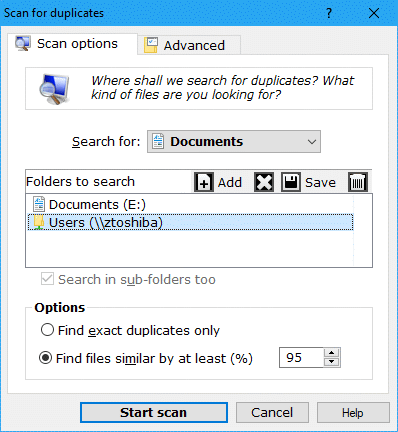
|
➂ Mark and remove duplicates
Use the checkboxes to mark duplicate items for removal, then remove them to clean up space. Use Mark wizard to choose the originals (which will be kept) depending e.g. on their folder location. Finally click Clean-up button to start deleting the marked duplicates. This is a standard procedure explained in detail in the documentation
Comparing document text requires system plugins that can extract text (IFilters) from various document formats like XLS, DOC, PDF, ODT, WPD etc. Usually the application that handles your documents automatically installs the necessary filters, but if you have a few missing you can download text preview filters.
